This course is run at the The University of NottinghamĀwithin the School of Computer Science & IT. The course is run by Graham Kendall (EMAIL : gxk@cs.nott.ac.uk)
If a request to open a file is done the ASCII path name is used to locate the correct directory entry. The entry in the directory contains all the information needed to access the file. For example, using a contiguous allocation scheme the directory entry will contain the first disc block (all other disc blocks can be found from there).
The same is true for linked list allocations.
For an i-node implementation the directory entry contains the i-node number
which, once loaded into memory, can be used to access the file.
Therefore, the only job of the directory entry is to provide a mapping from
an ASCII filename to the disc blocks that contain the data.
In addition, the directory entry may contain the attributes of the file. This is the case for an i-node implementation but other schemes may hold this information in the directory entry itself, or may provide a pointer to this information.
To give an example, we will look at how two directory systems are implemented; MS-DOS and UNIX.
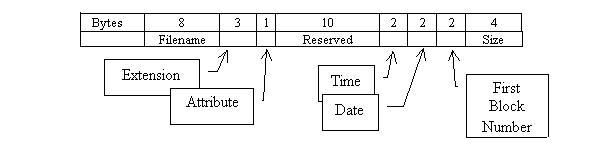
Under MS-DOS a directory entry is 32 bytes long. It is split as follows
|
The most important part (for our present discussions) is the first block number. This is a pointer to the data structure shown above when we discussed linked list allocation using an index.
We should also state, for completeness, that MS-DOS allows directories within directories, leading to a tree like structure.
For the interested student (Tanenbaum, 1992) goes into the implementation of
the MS-DOS file system in a lot more detail than we have done here.
A typical UNIX system directory entry just contains an i-node number and a filename. Unlike MS-DOS, all its attributes are stored in the i-node so there is no need to hold this information in the directory entry.
| Bytes | 2 | 14 |
| i-node | Filename |
The only other detail we should cover is how an i-node is located from its number. In fact, it is very simple. All the i-nodes have a fixed location on the disc so locating an i-node is a very simple (and fast) function.
To give us a better understanding let us consider how UNIX locates a file when given an absolute path name.
Assume the path name is /user/gk/ops/notes.
The procedure operates as follows.
· The system locates the root directory i-node. As we said above, this is easy as the entry is on a fixed place on the disc.
· Next it looks up the first path entry (user) in the root directory, to find the i-node number of the file /user.
· Now it has the i-node number for /user it can access the i-node data to locate the next i-node number (i.e. for /gk).
· This process is repeated until the actual file has been located.
Accessing a relative path name is identical except that the search is started
from the current working directory.
| Last Page | Back to Main Index | Next Page |
ĀLast Updated : 23/01/2002